Bear's House
資訊科技
認識中文字元碼
十、中文標準交換碼(CNS 11643)
(一)發展過程
民國69年9月國科會邀集國內字元編碼學者專家於溪頭開會,達成初步原則並據以呈報行政院核定《國家中文資訊標準交換碼編碼原則》。70年9月2日行政院函令國科會依據前述原則,邀集教育部、中央標準局及行政院主計處電子處理資料中心組成專案作業小組,積極推動中文字元編碼工作。71年7月專案作業小組曾編定常用中文字碼一種,但所收字數不夠。72年5月9日「行政院資訊推動小組」再次確立編碼方式,隨即於5月12日組成編碼技術作業小組,針對既定的編碼原則,研討編碼細則,10月底完成《通用漢字標準交換碼》,並決議試用兩年。
試用期滿後,國科會與主計處於74年8月邀集各相關單位與業者組成技術小組,檢討試用結果、修訂編碼原則後重編,75年3月獲行政院核定,正式公布實施。同年8月中央標準局將「通用漢字標準交換碼」頒布為國家標準,編號為「CNS 11643」。第一版的CNS 11643共收錄了13,051個中文字,分屬兩個字面。CNS 11643第一版公布之後不久,各機關即發現13,051個中文字無法滿足各自業務電腦化所需,因而紛紛自行造字。主計處電子處理資料中心於是彙整各機關自造字,於77年另外公佈了6,148個使用者加字及其編碼。
為因應各界對擴大中文字元集的需要,中央標準局於民國79年委託資訊工業策進會擴編CNS 112643,由原來的兩個字面(13,051字)大幅擴編為七個字面(48,027字)。CNS 11643第二版於81年5月公佈,同時更名為「中文標準交換碼」(Chinese Standard Interchange Code,以下簡稱為CSIC)。隨著戶政系統上線提供服務,民眾姓名用字的迅速增加,以及CSIC與ISO/IEC 10646字集同步化的需求,使得CNS 11643有必要再次擴編。民國92年初,標準檢驗局委託財團法人中文數位化技術推廣基金會再度擴編CNS 11643。CSIC第三版的編碼字面數由第二版的七個字面擴編為15個字面,中文字集也從原來的四萬八千餘字增加到約十萬字。此外,為了一勞永逸的解決可編碼字面容量飽和的問題,CNS 11643第三版也將編碼空間由第一版原先所規定的16字面增加到80個字面。【註:標準檢驗局係由經濟部原中央標準局的標準業務部門和商品檢驗局整併之後所新設立的機關。】
(二)編碼格式與編碼結構
CSIC遵循ISO/IEC 2022所規定的七位元94圖形字元式多位元組延伸編碼格式(詳見第三章),採兩位元組編碼,如圖10-1所示。CSIC編碼的一個位元組雖然原則上只有七個位元,但為了配合電腦與通訊一個位元組為八個位元的現實情況,特別將兩個位元組各增加一個設為“0”的前導位元,如圖10-1中所示的位元b16和b8。CSIC的正規字元碼格式為:
H4H3H2H1
其中,H4H3為字列位元組的十六進制數值,H2H1為字格位元組的十六進制數值。
|
|
||||||||||||||||
|
|
||||||||||||||||
|
字列位元組 |
字格位元組 |
圖10-1 CSIC的編碼格式
根據ISO/IEC
2022的規定,CSIC正規字元碼每一位元組只能使用21h∼7Eh的94個編碼位置。因此,CSIC的正規字元碼的編碼空間為94個字列,每字列94個字格(亦即碼位),合計94×94=8,836個碼位,明顯無法因應中文字元數以萬計的編碼需求。因此,CSIC採用多字面編碼結構,並藉助ISO/IEC 2022所規定的逸出順序和
調用控制符切換字面(詳見第三章的第二節)。由於不同字面的相同CSIC正規字元碼代表不同的中文字(例如:第1字面的字元碼454Ah為中文字「日」,而第2字面的字元碼454Ah卻是中文字「碇」),因此CNS
11643第三版另外規定了CSIC延伸字元碼以做為字元的唯一字元碼。CSIC延伸字元碼為正規字元碼之前附加該編碼字元所屬字面的字面指示碼,其格式為:
H6H5H4H3H2H1
其中,H6H5為字面指示碼,其值為01h∼50h,依序代表第1∼第80字面;H4H3H2H1為正規字元碼。
CNS 11643第三版規定了總共80個字面,其編碼空間總計為8836×80=706,880個碼位,但目前真正收容字元者僅前15個字面,如下所述(字表詳見CNS 11643中文標準交換碼碼本):
-
第1字面:2121h∼4243h為符號區,包括全形空格、全形標點符號、各種括號、註記符號、正字標記、標線符號、數學符號、性別符號、邏輯符號、箭頭符號、貨幣及單位符號、圖塊符號、製表符號、全形阿拉伯數字、全形羅馬數字、中國記帳數字、全形英文字母、全形希臘字母、國語注音符號及擴充、數字序列符號、康熙字典214部首、日文平假名及片假名、羅馬字音特別符號(即台語白話字)等;
4321h∼7D4Bh為常用中文字區,包括教育部《常用國字標準字體表》4,808字,以及取材自國中小教科書的常用字593字,總計為5,401個字。 -
第2字面:2121h∼7244h為次常用中文字區,包括教育部《次常用國字標準字體表》裡的中文字,以及罕用字體表中使用頻率較高的中文字,總計7,650個字。
-
第3字面:2121h∼6246h為罕用中文字區,包括主計處電子處理資料中心所整裡的政府機關用字、教育部所提供的罕用字和異體字,總計6,148個字;
6247h∼672Ah為罕用中文字區,包括香港地區及美國國會圖書館用字,總計247個字。 -
第4字面:2121h∼6E5Ch為罕用中文字區,包括戶政用字及資訊業界用字,總計7,298個字。
-
第5字面:2121h∼7C51h為罕用中文字區,包括教育部所公布之罕用字但未收錄於前四個字面者,總計8,603個字。
-
第6字面:2121∼647A為罕用中文字區,包括教育部所公布之異體字,其總筆畫數不超過14劃且未收錄於前五個字面者,總計6,388個字。
-
第7字面:2121h∼6655h為罕用中文字區,包括教育部所公布之異體字但未收錄於前六個字面者,總計6,388個字。
-
第8字面:為符號區,包括UCS-BMP的各種語文字母與符號原未收錄於本標準者。
-
第9字面:為符號區,包括UCS-BMP的各種語文字母與符號原未收錄於本標準者。
-
第10字面:為罕用中文字區,包括UCS第2字面CJK認同表意文字原未收錄於本標準者。
-
第11字面:為罕用中文字區,包括UCS第2字面CJK認同表意文字原未收錄於本標準者。
-
第12字面:為罕用中文字區,目前收錄戶政用字。
-
第13字面:為罕用中文字區,目前收錄戶政用字。
-
第14字面:為罕用中文字區,除4B6Dh∼6D79h為UCS-BMP表意文字原未收錄於本標準者之外,其餘皆為戶政用字。
-
第15字面:為罕用中文字區,目前收錄戶政用字。
-
第16字面:為專用字區,供使用者自行加字,CNS 11643不規定此字面的編碼字元。
-
第17∼第80字面:保留供未來擴充字集使用。
(三)字面的指定與切換
由於CSIC正規字元碼長度僅有兩個位元組,無法提供字元究竟屬於哪個字面的訊息,導致一個CSIC正規字元碼可能代表多達80個字元。現階段,CSIC收錄的字元只編碼到第15字面,一個字元碼可能代表多達15個字元。使用CSIC時,因而必須先藉助ISO/IEC 2022的逸出順序控制符指定字面和利用 調用控制符切換字面,才可使得每個CSIC正規字元碼都能代表唯一的一個字元。換言之,從ISO/IEC 2022圖形字元碼延伸編碼結構的觀點來看,CSIC比較像是80個字元集和碼的集合。CSIC的字面指定和切換,因此可以看做是字元集和碼的指定與切換。CSIC的字面指定與切換方式如圖10-2所示,各控制符詳見圖3-4。
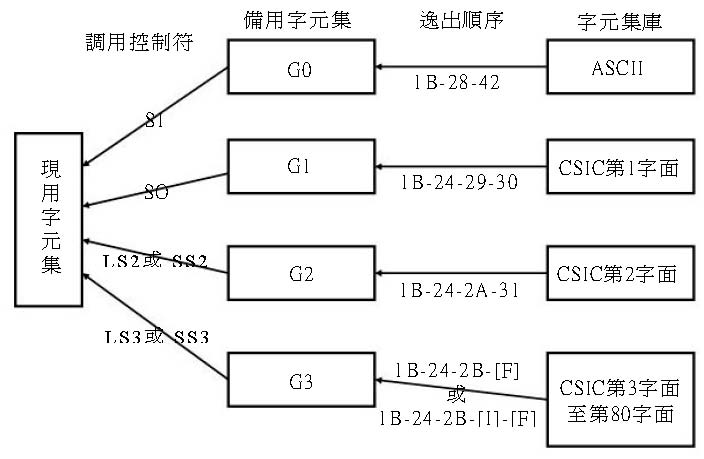
圖10-2 CSIC字面的指定與切換方式
ASCII為作業系統、資訊處理系統所必備的預設字元集,CSIC第1字面收錄常用中文字、第2字面收錄次常用中文字,這兩字面足以涵蓋一般中文資料檔裡絕大多數的中文字。因此實務上可依據CNS 11643之4.1節及其附件2的規定,使用CSIC時先利用逸出順序“1B 28h 42h”(1Bh為控制字元ESC的ASCII碼)指定將ASCII的字元集和字元碼載入備用字元集G0、利用逸出順序“1Bh 24h 29h 47h”指定將CSIC第1字面的字元集和碼載入G1、利用逸出順序“1Bh 24h 2Ah 48h”指定將第2字面的字元集和碼載入G2,以及視需要利用逸出順序“1Bh 24h 2Bh [F]”指定將第3至第16字面的字元集和碼擇一載入G3,或是視需要利用逸出順序“1Bh 24h 2Bh [I] [F]”指定將第17至第80字面的字元集和碼擇一載入G3。適用於CSIC第1∼16字面的最終位元組[F]如圖10-3所示,而適用於CSIC第17∼80字面的專用中間字元[I]及專用最終位元組[F]則如圖10-4所示。【註:最終位元組[F]即第三章的終結位元組f;另『正式[F]』係指該最終位元組已向ISO註冊,『專用』意指該中間字元或最終位元組只能適用於我國境內。】
|
|
圖10-3 CSIC第1∼16字面的最終位元組[F]
|
|
|
|
圖10-4 CSIC第17∼80字面的專用中間字元[I]及專用最終位元組[F]
在僅限於使用ASCII和CSIC的前提下,可載入備用字元集G0、G1和G2的候選字元集各只有一個,這些字元集一經載入,即成為不會被替換的常駐字元集。因此,可採取預設指定的方式,在啟動中文系統時,一併將ASCII和CSIC的第1、第2字面分別載入G0、G1與G2,無須等到相關的逸出順序出現才進行字元集和碼的載入動作。藉由這樣的預設指定,即可省略“1Bh 28h 42h”、“1Bh 24h 29h 47h”和“1Bh 24h 2Ah 48h”三個逸出順序,直接利用 調用控制符SI切換現用字元集為ASCII、利用控制符SO切換現用字元集為CSIC第1字面、利用控制符LS2(即1Bh 6Eh)切換現用字元集為CSIC第2字面,或是利用控制符SS2(即1Bh 4Eh)暫時選擇CSIC第2字面的某一個字元。但就G3而言,由於可載入G3的候選字面目前多達14個(已編碼的CSIC第3∼15字面和第16字面自造字),因此不能省略逸出順序,否則將會把錯誤的字面載入G3。換言之,遇有第3∼第16字面的字元時,需根據該字元所屬字面,先以對應的逸出順序控制碼指定字面載入G3,接著再利用控制符LS3(即1Bh 6Fh)切換現用字元集為指定字面,或是利用控制符SS3(即1Bh 4Fh)暫時選擇指定字面的某一個字元。
CSIC的應用例如圖10-5所示。在ASCII和CSIC並存的環境裡,如果前後兩個字元同屬一個字面時(ASCII也看做一個字面),後字元可維持與前字元相同的編碼格式(ASCII為單位元組、CSIC為雙位元組)。如果前後兩字元分屬不同字面時,就必須在後字元的前面(即兩字元之間)插入 調用控制符甚或逸出順序控制符以切換字面,說明如下:
-
當後字元為ASCII(已載入G0)而前字元不是ASCII時,兩者之間必須插入 調用控制符SI(字元碼為0Fh)。
-
若後字元屬於CSIC第1字面(已載入G1)而前字元不是,則兩者之間必須插入 調用控制符SO(字元碼為0Eh)。
-
當後字元屬於CSIC第2字面(已載入G2)而前字元屬於其它字面時,兩者之間應插入 調用控制符LS2(字元碼為1Bh 6Eh)或SS2(字元碼為1Bh 4Eh)。
-
若後字元屬於第3至第16字面,則兩者之間應先依據該字元所屬字面插入逸出順序“1Bh 24h 2Bh [F]”,再插入調用控制符LS3(字元碼為1Bh 6Fh)或SS3(字元碼為1Bh 4Fh)。
-
若後字元屬於第17至第80字面,則兩者之間應先依據該字元所屬字面插入逸出順序“1Bh 24h 2Bh [I] [F]”,再插入調用控制符LS3(字元碼為1Bh 6Fh)或SS3(字元碼為1Bh 4Fh)。
|
0F (SI) |
43 C |
4E N |
53 S |
31 1 |
31 1 |
36 6 |
34 4 |
33 3 |
0E (SO) |
4466 中 |
4546 文 |
6D3A 標 |
646D 準 |
4728 交 |
|
5F50 換 |
6E23 碼 |
5152 是 |
4B6D 依 |
0F (SI) |
43 C |
4E N |
53 S |
35 5 |
32 2 |
30 0 |
35 5 |
0E (SO) |
452F 及 |
0F (SI) |
|
43 C |
4E N |
53 S |
37 7 |
36 6 |
35 5 |
34 4 |
0E (SO) |
4466 之 |
5D3D 規 |
6E2F 範 |
4854 而 |
4C31 制 |
5354 訂 |
2122 , |
|
0F (SI) |
43 C |
4E N |
53 S |
31 1 |
31 1 |
36 6 |
34 4 |
33 3 |
0E (SO) |
5972 將 |
215A 『 |
1B-4E SS2 |
2539 佴 |
215B 』 |
|
6E3E 編 |
4D75 於 |
5C49 第 |
4428 二 |
4773 字 |
5372 面 |
2122 , |
4C27 其 |
6E3E 編 |
6E23 碼 |
5233 為 |
0F (SI) |
32 2 |
35 5 |
33 3 |
|
39 9 |
0E (SO) |
2122 , |
5972 將 |
215A 『 |
1B-24-2B-32 逸出順序:第3字面→G3 |
1B-4F SS3 |
5972 鈢 |
215B 』 |
6E3E 編 |
4D75 於 |
||||
|
5C49 第 |
4435 三 |
4773 字 |
5372 面 |
2124 。 |
|
|
|
|
|
|
|
|
|
|
圖10-5 CSIC的應用例
(四)EUC-CSIC
根據CNS 11643之4.2節和附件1的規定,可將CSIC延伸字元碼套入EUC-2編碼格式中而成為位元組標籤式中文內碼EUC-CSIC,如圖10-5所示。EUC-CSIC採EUC-2定長四位元組編碼。圖中,最左邊位元組為EUC-2識別符SS2,其值為8Eh,另外三個位元組則對應CSIC延伸字元碼。字列位元組和字格位元組為CSIC正規字元碼(H4H3H2H1),但必須分別將b16和b8都設為“1”,亦即字列位元組的值設為H4H3加上80h、字格位元組的值則設為H2H1加上80h。此外,字面位元組的值設為字面指示碼(H6H5)加上A0h,藉以避開控制字元集C1。
| B4 | B3 | B2 | B1 | ||||
|
|
|
|
||||
| EUC-2識別符 | 字面位元組 | 字列位元組 | 字格位元組 |
圖10-5 EUC-CSIC