Bear's House
資訊科技
認識中文字元碼
十一、Unicode與UCS(ISO/IEC 10646)
(一)緣起
隨著資訊科技的日趨普及,世界各國大多制訂了各自的字元碼。這些字元碼或是單位元組編碼,或是多位元組編碼,視各國語言的字元集大小而定。一般說來,單位元組字元碼大多採用ISO/IEC 8859系列的八位元單位元組字元碼,而多位元組交換碼則大多 遵循ISO/IEC 2022的編碼結構。不管如何,各國字元碼所呈現出來的景象是:相同或類似的字元碼各自表示不同的字元集(其中之最為ISO/IEC 8859系列標準,用同一套字元碼來表示多達十五種不同的字元集),造成嚴重的字元碼競合現象,因而阻礙資訊交流,跨國資訊業者甚至要為各種語言的字元碼量身製作(或修改)作業系統核心和應用程式。於是相關業者有了發展多語言整合性字元集和字元碼的構想。
為容納全世界各種語言的字元和符號,ISO的一些會員體於1984年發起制定新的國際字元集編碼標準。新標準由工作組ISO/IEC JTC1/ SC2/WG2負責擬訂(以下簡稱WG2),最後定案的標準名稱為“Universal Multiple-Octet Coded Character Set”(簡稱UCS),其編號則訂為ISO/IEC 10646。【註1】
依WG2原來的規畫,UCS的編碼結構係沿襲ISO/IEC 2022的八位元延伸編碼結構以避開C0和C1兩個控制碼區,但打破每個字元碼裡所有位元組的b8必須 都設為0或是都設為1的限制(詳見第三章),以提高編碼空間的使用率。同時,為了能有足夠的碼位以容納全世界各種語言的字元和符號,以及為了配合微處理器以8、16、32甚或64個位元為一個運算處理單位的趨勢,UCS的字元碼長度被規定為定長的 四個八位元(4 octets)。
ISO/IEC 10646草案初稿一經公佈,其編碼結構立即遭到美國部份電腦業者的反對。1988年初,美國Xerox公司的Joe Becker倡議以新的編碼結構另 行編訂世界性字元編碼標準:將電腦字元集編碼的基本單位由現行的七或八個位元一舉擴充為16個位元,並充分利用216=65,536個碼位以容納全世界各種語言的字元和常用符號。新的字元集編碼標準被命名為“Unicode”。一群來自Xerox公司和Apple公司的工程師組成工作小組,負責Unicode的原始設計工作。1991年元月,十多家電腦硬軟體、網路和資訊服務業者,包括:IBM、DEC、Sun Micro、Xerox、Apple、MicroSoft、Novell等知名公司,共同出資成立Unicode協會(The Unicode Consortium),並由協會設立非營利的Unicode公司。Unicode協會成立之後,將原先的工作小組擴編為Unicode技術委員會(UTC,Unicode Technical Committee),專責Unicode的字元 蒐集、整理、編碼等工作。推動Unicode成為國際標準的工作,則由Unicode公司負責。Unicode第一版草案於1989年9月發表,歷經多次修訂後,分別於1991、92年出版了Unicode標準(The Unicode Standard)第一版的第一冊(Unicode 1.0.0)、第二冊(Unicode 1.0.1)。
由於Unicode協會持續的遊說和施壓,WG2終於放棄原先選擇的ISO/IEC 2022八位元延伸編碼結構,改採Unicode的編碼方式,亦即連續編碼不再避開C0和C1控制碼區。1991年10月,歷經幾個月的協商之後,WG2和Unicode協會達成協議,將Unicode併入UCS成為第0字面。之後各國語言字元的搜集、整理和編碼等工作轉由WG2主導,而Unicode協會則積極協助WG2,但雙方仍然各自出版自己的編碼標準。由於雙方標準的整合是在Unicode標準第一版第一冊出版之後才展開的,因此該版次標準的第二冊特別在第一章裡說明了為因應合併工作所做的編碼區和字元集修訂項目。
UCS所收錄的字元包括拼音文字字元、表意文字字元、各種符號和控制字元四大類。對於收錄新增字元的作業方式,WG2雖然沒有明文規定,但經多年運作之後已建立起兩套不成文的規範,其中針對拼音文字字元、符號和控制字元部分的整理和編碼程序大抵如下:
-
由會員體、專業團體或個別專家向WG2提 案,申請新增字元。
-
WG2收到新增字元提案後隨即送請相關專家審查,專家審查通過的新增字元提案交由WG2會議審議,WG2審議通過的字元交由UTC進行編碼。
-
UTC編碼的新增字元再送回WG2審議後,交由國家會員體票決通過後正式公布修正文件(amendment)。
-
累積相當程度的修正案之後,WG2會製作新一版ISO/IEC 10646的草案,該草案經WG2會議通過後交由國家會員體票決,票決通過之後草案定稿,再經SC2批准後出版最新版本的ISO/IEC 10646。
由於WG2的核心成員大多是歐美人士,並不熟悉表意文字,因此WG2之下另設表意文字書記組(Ideograph Rapporteur Group, IRG)專責表意文字字元的蒐集和整理比對工作。 所謂表意文字其實就是東亞各國所使用發源於中國的漢字,主要包括台灣、中國大陸、日本、南北韓、越南、新加坡和港澳地區所使用或曾經使用過的漢字。針對表意文字字元部分的整理和編碼程序大抵如下:
-
IRG會員體提出新增字元計畫,經IRG會議通過後報請WG2核備。
-
IRG會員體就WG2所同意的新增表意文字字元案,提交各會員體的來源字集。
-
IRG編輯組(由各會員體派人員組成)彙整各會員體來源字集,並反覆進行比對、認同和勘誤工作,最後形成擬新增至UCS的認同表意文字字元集。
-
整理完成的新增認同表意文字字元集提交WG2審議,依慣例WG2會依據IRG所提出的表意文字字元集照案通過予以收錄編碼。
Unicode協會持續積極參與WG2的各項工作,通常新版本的ISO/IEC 10646草案一經WG2會議審議通過之後,Unicode協會就會據以編輯和印行新一版的Unicode標準。相對的,新版ISO/IEC 10646卻還得再經過國家會員體票決和SC2核可兩道關卡,所以Unicode標準通常要比相對應版本的ISO/IEC 10646早幾個月出版。ISO/IEC 10646與Unicode兩者,其字元集和字元碼完全相同,但兩者的章節編排和文字內容卻大異其趣。ISO/IEC 10646的章節和文字內容嚴格遵守『標準』的寫法,讀來詰屈聱牙,就像法律文件般的難懂,而且不交代所編碼的每一個語言字元集的概況。相對的,Unicode標準就像是ISO/IEC 10646的實作指引(implementation guide)和導讀,不只交代了技術細節,而且像百科全書般的介紹了各種語言的概況。
(二)編碼結構與字元集
UCS字元碼的正規形式(簡稱為UCS-4)為32個位元,劃分成四個八位元,如圖11-1所示。這四個八位元,由左而右命名為群組八位元(G-octet)、 字面八位元(P-octet)、列八位元(R-octet)和格八位元(C-octet),分別代表編碼結構中的群組(group)、字面(plane)、列(row)與格(cell)。 圖11-2所示為整個UCS的編碼空間示意圖。UCS規定其字元碼的b32必須為0,因而整個編碼空間可區分為128個群組(群組八位元的值為00∼7Fh),每一群組由256個字面所組成( 字面八位元為00∼FFh),每一個字面由256列所組成(列八位元為00∼FFh),每一列則包含256格(格八位元為00∼FFh),每一格為一個碼位。此外,UCS還規定每一個字面的最後兩個碼 位FFFEh和FFFFh,保留不用。所以,UCS整個編碼空間總共256×128=32,768個字面,每個字面為256×256-2=65,534個碼位,合計65534×32768=2,147,418,112個碼位。
| 位元名稱 |
b32 … … … … … … b25 |
b24 … … … … … … b17 | b16 … … … … … … b9 | b8 … … … … … … b1 | ||||
|
|
|
|
圖11-1 UCS字元碼的正規形式
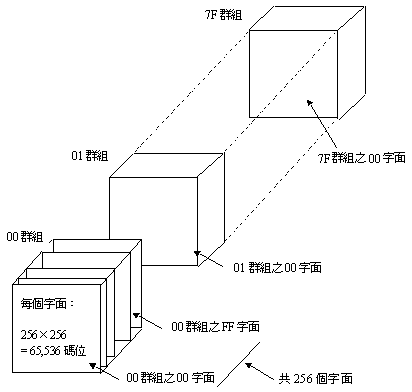
圖11-2 UCS全部的編碼空間
UCS的第0群組的第0字面(群組八位元和字面八位元的值都為00h)稱為「基本多語文字面」(BMP,Basic Multi-lingual Plane),BMP之外的32,767個字面區分為輔助字面(supplementary planes)和專用字面(private use planes)。輔助字面用以收容WG2陸續收集、整理和編碼的各國語文字元,專用字面的內容WG2不予規定,保留供使用者自行添加UCS未收容的字元。專用字面共8,226個,包括00h群組的0Fh、10h和E0∼FFh共計34個字面,以及60∼7Fh共32個群組的8,192個字面。除了這8,226個專用字面之外,其餘的24,541個字面都是輔助字面。當電腦系統只使用BMP的字元碼時,可以省略 群組八位元和字面八位元,因而而將字元碼由32個位元縮短為16個位元,稱為UCS字元碼的基本字面形式(可簡稱為UCS-2),其實也可視同於習稱的Unicode。
UCS所有字面中,目前僅有第0群組的第0字面(BMP)、第1字面、第2字面和第14字面真正收容編碼字元。BMP的編碼字元概況,依其UCS-2編碼序介紹如下:
-
0000∼007Fh:基本拉丁字母區。其中0000∼001Fh為C0控制碼,0020h為空格(space),0021∼007Eh為ASCII圖形字元,007Fh為控制碼DEL。事實上,這128個字元碼只要把前八個位元去掉就可變成習見的八位元形式的ASCII碼。
-
0080∼00A0h:控制碼區。其中0080∼009Fh為C1控制碼,00A0h為不中斷空格(no-break space)。
-
00A1∼1FFFh:拼音文字區。收容基本拉丁字母之外的各種拼音文字字元,包括歐洲各國語言、國際音標、間隔修飾字母、組合附加記號、希臘文、斯拉夫文、 亞美尼亞文、希伯來文、阿拉伯文、敘利亞文、馬爾地夫文、印度各地方言、斯里蘭卡文、泰文、寮文、藏文、緬甸文、喬治亞文、韓文音符、衣索匹亞文、印地安語文 、高棉文、蒙文等。
-
2000∼28FFh:符號區。收容各種符號,包括標點符號、上下標、錢幣符號、 符號用組合附加記號、似字母符號、數字、箭頭、數學運算符、工程符號、光學辨識符號、帶圈或帶括符的文數字、表格繪製符號、地理圖示、盲用點字、裝飾圖形等。
-
2E80∼33FFh:中日韓符號區。收容康熙字典部首、中日韓輔助部首、注音符號、日本假名、韓文音符,中日韓的符號、標點、帶圈或帶括符文數字、月份,以及日本的假名組合、單位、年號、月份、日期、時間等。
-
3400∼4DFFh:中日韓認同表意文字擴充A區,總計收容6,582個中日韓漢字 和易經六十四卦符號。
-
4E00∼9FFFh:中日韓認同表意文字區,總計收容20,902個中日韓漢字。
-
A000∼A4FFh:彝族文字區,收容中國南方彝族文字和字根。
-
AC00∼D7FFh:韓文拼音組合字區,收容以韓文音符拼成的文字。
-
D800∼DFFFh:S區,專用於UTF-16,詳情後敘。
-
E000∼F8FFh:專用字區,其內容WG2不予規定,保留供使用者自行添加UCS未收容的字元。
-
F900∼FAFFh:中日韓相容表意文字區,總計收容302個中日韓漢字。何謂相容表意文字,留待後敘。
-
FB00∼FFFDh:文字表現形式區,收容組合拉丁文字、希伯來文、阿拉伯文、中日韓直式標點、小符號、半形符號、全形符號等。
BMP同時收編拼音文字、符號和表意文字。但全世界古今各種語言文字和符號的數量何其龐大,單靠BMP不足以容納。WG2截至目前為止所收集、整理的拼音文字和符號部分,扣除已編入BMP者,其餘全部編入第1字面, 包括一些古代語言的字母和數字、拜占庭和西洋音樂符號、太玄經符號、文數字符號等。第14字面目前只收錄了幾個用途未定的標籤字元。而表意文字部分扣除已編入BMP者,其餘全部編入第二字面,其內容為:
-
中日韓認同表意文字擴充B區:總計42,807個中日韓越漢字,編碼範圍為0002-0100∼0002-A836h。
-
中日韓相容表意文字擴充A區:收容被認同的CNS 11643字元527個,編碼範圍為0002-F800∼0002-FA16h。
IRG專責收集各國漢字字集,加以比對認同彙整成為整體性字集之後再向WG2提出。IRG各會員體所提出的漢字都源自中國,難免有些字的字形相同或極為近似。為了避免UCS編碼表出現重複字造成使用者困擾,IRG制訂了表意文字認同規則。凡是依規則應予認同的漢字,一律合併成一字賦予一個編碼。不過為了尊重各國對各自文字的主控權,BMP編碼表中 的中日韓認同表意文字區及中日韓認同表意文字擴充A區特地並列同一漢字不同來源的各自字形。
認同規則不僅運用於整合不同來源的漢字,同時適用於相同來源的漢字。例如,在我國中文碼國家標準CSIC(CNS 11643)的字集裡就收編了兩個極為相似的「圖」字,分別賦予兩個不同的碼1-6837h和6-5B5Bh,這兩個「圖」字,依認同規則必須合併為一個,於是後者被前者認同掉了。詳言之,CSIC的1-6837h和6-5B5Bh都對應到Unicode的5716h(或UCS的0000-5716h),但是Unicode的5716h卻只對應到CSIC的1-6837h。當我們把資料從CSIC碼轉換成Unicode,再由Unicode轉回CSIC碼時,將發生6-5B5Bh→5716h→1-6837h的結果,這種現象稱為去回轉碼(round-trip conversion)錯誤。解決之道無他,必須在Unicode或UCS字集中多加上被認同掉的字元並另外賦予編碼(稱為相容字元),做到CSIC字集與UCS字集一對一(但不必也無法做到映成)。UCS第2字面所收容的CSIC相容字集,就是我國為了達到正確去回轉碼的目的,經多年力爭所得成果。換言之,CSIC現有中文字集已全數編入UCS編碼表中。
(三)UTF-16與UTF-8
UCS的編碼空間雖然足以容納古今人類使用過的所有文字和符號,但目前真正被使用的文字或符號,其常用者都已編入BMP,它們的使用頻率可能超過99%甚至99.99%。換言之,就99%以上的使用者或使用場合而言,16位元的UCS-2(習稱Unicode)已是足敷需求,32位元的UCS-4正規編碼則顯得割雞用牛刀。UCS-4不只要比UCS-2佔用多一倍的記憶或儲存空間,而且在網路傳輸和資訊處理上也需花費比較長的時間。就經濟效益而言,將來電腦和網路選擇使用UCS-2的可能性,很明顯的要高於選擇使用UCS-4。問題是,在Unicode的世界裡,遇到必須使用相當罕用的UCS第1、第2字面甚至更後方字面的字元時,怎麼辦?ISO/IEC 10646所規定的解決方案稱為UTF-16或代理法(surrogates)。
UTF為“a UCS (or Unicode) Transformation Format”的縮寫,UTF-16意即把原為32位元的UCS-4字元碼轉換為兩或多個16位元的UCS-2字元碼。目前的 做法是組合兩個UCS-2字元碼來代表一個UCS-4字元碼(如圖11-3所示),所以又稱為代表法。兩個做為代表的UCS-2字元碼,位於前方(左方)者稱為高半字元,限定只能選用D800∼DBFFh當中之一,位於後方(右方)者稱為低半字元,限制只可從DC00∼DFFFh當中選擇。高低半字元的碼位各為1,024=4×256,因此UTF-16總計可提供(4×256)×(4×256)=16×65536個碼位,亦即16個字面。對BMP而言,當然無須使用UTF-16轉碼,所以UTF-16主要應用於UCS的第1∼第14字面(因為第15字面為專用字面,WG2不予編碼)。
|
高半字元 ( D800∼DBFFh ) |
低半字元 ( DC00∼DFFFh ) |
圖11-3 組合兩個UCS-2字元碼以代表一個UCS-4字元碼
將UCS-4字元碼(編碼範圍0001-0000∼000E-FFFFh)以UFT-16轉換成UCS-2字元碼組合形式的規則如圖11-4所示,圖中為了方便對應16進制,特別將字元碼表現成每4個位元一組,中間以短槓分隔。轉換方式不難,將原來的32位元UCS字元碼,從右往左取出10個位元(即圖中的Y10∼Y1)前頭附加上特定的6個位元110111,即成為低半字元。接著往左取出6個位元(即圖中的Y16∼Y11)做為高半字元的最低6個位元,然後再往左取出4個位元(即圖中的Z4∼Z1,相當於Y20∼Y17,其值可顯示第0∼第15字面),將其值減1,置於剛才那6個位元的左方,最後在最前方附加上特定的6個位元110110,即成為高半字元。以上所介紹的是UTF-16轉換的觀念,至於UTF-16的轉換公式和還原公式,請詳見UCS標準或Unicode標準。
|
0000-0000-0000-X4X3X2X1-Y16Y15Y14Y13-Y12Y11Y10Y9-Y8Y7Y6Y5-Y4Y3Y2Y1 |
|
↓UTF-16轉換 |
|
1101-10Z4Z3-Z2Z1Y16Y15-Y14Y13Y12Y11(高半字元) |
|
+ |
|
1101-11Y10Y9-Y8Y7Y6Y5-Y4Y3Y2Y1 (低半字元) |
|
(註:Z4Z3Z2Z1=X4X3X2X1-1) |
圖11-4 UTF-16的轉換規則示意
請特別注意,UTF-16係針對UCS-2世界所設計的。換言之,當網際網路和大部分的電腦都已經放棄八位元的ASCII而改為採用16位元的Unicode之後,UTF-16才可用來表現UCS第1字面∼第14字面的字元碼。很不幸的事實並非如此,現在是ASCII的世界而非16位元Unicode的世界。當 任何UCS-2字元碼離開溫室(某個以16位元Unicode為內碼的作業系統或應用程式)之後,馬上會被網路設備切成兩個八位元的位元組,並嚴密檢查是否有任何位元組為C0控制碼,至少數千個UCS-2字元碼將因此變的殘缺不全。為了能讓UCS-2和UCS-4字元碼能安然通行於ASCII世界,ISO/IEC 10646特別規定了UTF-8以解決問題。UTF-8意即把原為32位元的UCS-4字元碼或原為16位元的UCS-2字元碼轉換為多個八位元的位元組。
利用UTF-8轉碼規則可將一個UCS-2或UCS-4字元碼轉換成1∼4個位元組的編碼,如圖11-5所示。UTF-8的轉換規則很簡單:若原始字元碼位於0000∼007Fh(或0000-0000∼0000-007Fh)的範圍內,則直接截取最右 八個位元即可,轉換結果其實就是ASCII碼。若原始字元碼大於007Fh(或0000-007Fh),亦即超出ASCII範圍時,就必須轉換成2∼4個位元組。UTF-8規定,以轉換後第1位元組 前導連續設為“1”的標記位元的數目表示轉換成幾個位元組:“110”表示轉換結果為兩個位元組,“1110”表示三個位元組,而“11110”則表示四個位元組。至於跟隨在標記位元之後設為“0”的位元,其作用在分隔標記位元和字元碼位元。第2∼第4位元組起頭兩個位元被設為“10”當做識別,剩下的6個位元才做為字元碼位元使用。總計, 兩位元組UTF-8字元碼剩下11個字元碼位元,可用以轉換0080∼07FFh的原始字元碼。三位元組剩下16個字元碼位元,可用以轉換0800∼FFFFh的原始字元碼。而 四位元組則剩下21個字元碼位元,可用來轉換0001-0000∼001F-FFFh(即UCS第1字面∼第31字面)的原始字元碼。請注意,雖然四位元組的UTF-8編碼可包容1∼3個位元組的碼, 三位元組的編碼可包容1∼2個位元組的碼,以及兩位元組的編碼可包容單位元組的碼,但是UTF-8規定轉碼時必須選擇最短者。換言之,ASCII區只能轉換成單一個位元組,0080∼07FFh的原始字元碼只能轉換成 兩個位元組長度,依此類推。
|
原始字元碼 |
轉換結果 |
|
000000000x7x6x5x4x3x2x1 |
0x7x6x5x4x3x2x1 (第1位元組) |
|
00000x11x10x9x8x7x6x5x4x3x2x1 |
110x11x10x9x8x7 (第1位元組) 10x6x5x4x3x2x1 (第2位元組) |
|
x16x15x14x13x12x11x10x9x8x7x6x5x4x3x2x1 |
1110x16x15x14x13 (第1位元組) 10x12x11x10x9x8x7(第2位元組) 10x6x5x4x3x2x1 (第3位元組) |
|
00000000000x21x20x19x18x17- x16x15x14x13x12x11x10x9x8x7x6x5x4x3x2x1 |
11110x21x20x19 (第1位元組) 10x18x17x16x15x14x13(第2位元組) 10x12x11x10x9x8x7 (第3位元組) 10x6x5x4x3x2x1 (第4位元組) |
圖11-5 UTF-8的轉換規則示意
ISO/IEC 2022式交換碼(例如CNS 11643、GB 2312、JIS X 0208等)必須使用逸出順序和調用控制符,藉以切換ASCII和多位元組交換碼的各個字面,導致這些交換碼變成非定長碼,不利於資料的檢索與處理。因此台灣、中國大陸、日本等國的資訊業者都各自依據交換碼或其字元集另行發展了對應的定長內碼。以台灣為例,Big5係採用CSIC第一字面及第二字面字元集另行設計的兩位元組內碼、EUC-CSIC則是將CSIC套進EUC-3格式中所設計出來的四位元組內碼。Unicode設計之初原想裡外通吃、內碼和交換碼兼顧,但事與願違。由於ASCII影響力深入且遍及電腦和網路通訊的硬軟體,在資訊與通訊領域內只要涉及字元(包括圖形字元和控制字元)的標準與協定,無不受到ASCII的影響與制約。不幸的,UCS和ASCII、ISO/IEC 2022和ISO/IEC 6429都無法完全相容,因此UCS-2、UCS-4和UTF-16迄今都只能當做內碼使用。只有UTF-8因為不抵觸ASCII世界的標準和協定,才得以扮演UCS的交換碼角色,代替UCS-2和UCS-4擔當起資訊交換的任務。
註1:JTC1係由ISO和IEC雙方協議共組的第一聯合技術委員會(Join Technical Committee One),負責制訂與資訊處理、資訊技術相關的國際標準;JTC1/SC2為設於JTC1之下的第二分組委員會(Sub-Committee Two);而JTC1/SC2/WG2則是JTC1/SC2之下的第二工作組(Working Group Two)。在我國,經濟部標準檢驗局設有對應ISO/IEC JTC1/SC2的組織,稱為資訊及通信國家標準技術委員會,而對應ISO/IEC JTC1/SC2/WG2者,稱為中文資訊標準分組委員會。